Pytorch中知识点03
本文记录一下在调试模型过程中的一些 Pytorch 框架和 python 相关知识点。
- 报错:
TracerWarning: Converting a tensor to a Python index might cause the trace to be incorrect … This means that the trace might not generalize to other inputs!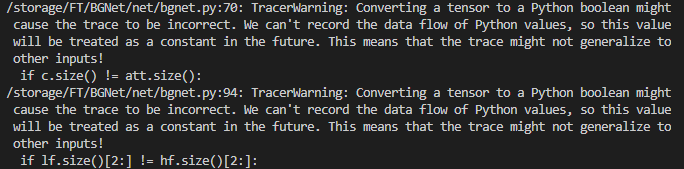
解决方案:将对应位置条件语句删除
# if c.size() != att.size():
# att = F.interpolate(att, c.size()[2:], mode='bilinear', align_corners=False)
# 删除if语句
att = F.interpolate(att, c.size()[2:], mode='bilinear', align_corners=False)
# if lf.size()[2:] != hf.size()[2:]:
hf = F.interpolate(hf, size=lf.size()[2:], mode='bilinear', align_corners=False)参考资料:
- TracerWarning: Converting a tensor to a Python index might cause the trace to be incorrect…This means that the trace might not generalize to other inputs!
- TracerWarning: Converting a tensor to a Python index might cause the trace to be incorrect. We can’t record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! #2836
- Torch JIT Trace = TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect
2.报如下错误:

其原因在于数据集的大小除以batch_size余1,最后只包含单个数据的batch无法完成batch_norm操作。
解决方案:更改batch_size。
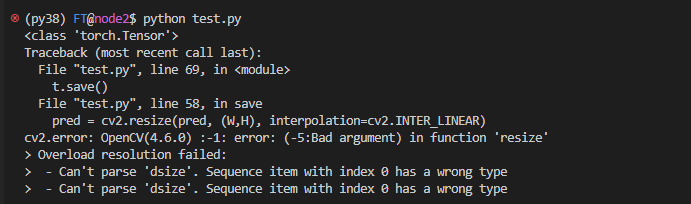
其原因为(W,H)中数据类型不对,应该将torch.Tensor转为int。由于H和W均为一维Tensor,可以通过以下代码实现:
H, W = H.item(), W.item()4.当通过`state_dict = model_zoo.load_url(url_map_[model_name]`在线下载预训练的模型权重文件时,出现`urllib.error.HTTPError: HTTP Error 503: Egress is over the account limit.`错误。 参考资料:
- 原因:状态码为
503 Service Unavailable,表示临时的服务器维护或者过载,服务器当前无法处理请求,这个情况是暂时的,会在一段时间后恢复(实际上过了好多天都没修复) - 解决方案:因为调用
model_zoo.load_url()时会打印出该权重文件的下载地址和保存路径,可以通过手动下载并放入该路径来解决该问题,如下图所示

5.报错:参考资料:
Cannot interpret '<attribute 'dtype' of 'numpy.generic' objects>' as a data typex1 = torch.rand((4, 256, 80, 80))
x2 = torch.rand((4, 512, 40, 40))
x3 = torch.rand((4, 1024, 20, 20))
x4 = torch.rand((4, 2048, 10, 10))x = torch.randn((4, 3, 320, 320))x = torch.ones(2, 3)x = torch.zeros(2, 3)9.张量最大值和最小值:参考资料:
- BCE Loss vs Cross Entropy - vision - PyTorch Forums
- [Learning Day 57/Practical 5: Loss function — CrossEntropyLoss vs BCELoss in Pytorch; Softmax vs sigmoid; Loss calculation | by De Jun Huang | dejunhuang | Medium](https://medium.com/dejunhuang/learning-day-57-practical-5-loss-function-crossentropyloss-vs-bceloss-in-pytorch-softmax-vs-bd866c8a0d23#:~:text=Difference in purpose (in practice,probability%2C you should use BCE.&text=We cannot use sigmoid for,CrossEntropyLoss as the loss function.)
- BCELoss — PyTorch 1.13 documentation
- CrossEntropyLoss — PyTorch 1.13 documentation
# 最大
x.max()
# 最小
x.min()# 原始tensor x
x = torch.randn((366, 400)) # shape: 366, 400
# 扩充维度
x = x.unsqueeze(0) # shape: 1, 366, 400
# 复制通道
x = x.repeat(3, 1, 1) # shape: 3, 366, 400
# 压缩维度
x = x.squeeze(0) # shape: 3, 366, 400 不能压缩非1的维度
x = torch.randn((1, 366, 400))
x = x.squeeze(0) # shape: 366, 400gaussian_2D = get_gaussian_kernel(k_gaussian, mu, sigma)
self.gaussian_filter = nn.Conv2d(in_channels=1,
out_channels=1,
kernel_size=k_gaussian,
padding=k_gaussian // 2,
bias=False)
self.gaussian_filter.weight[:] = torch.from_numpy(gaussian_2D)Leaf variable was used in an inplace operationdef forward(self, x):
B, C, H, W = x.shape
for i in range(B):
xi = x[i, ...][None, ...]
xi = self.net(xi)x1 = torch.randn((1,3,320,320)) # x1.shape: (1,3,320,320)
x2 = torch.randn((1,3,320,320)) # x2.shape: (1,3,320,320)
x = torch.cat((x1,x2), dim=0) # x.shape: (2,3,320,320)x1 = torch.randn((1,3,320,320)) # x1.shape: (1,3,320,320)
x2 = torch.randn((1,3,320,320)) # x2.shape: (1,3,320,320)
x = torch.stack((x1, x2), dim=0) # x.shape: (2,1,3,320,320)a = torch.randn((16,3,320,320)) # (16,3,320,320)
a1 = a[0] # (3,320,320)
a2 = a[0:1] # (1,3,320,320)
a3 = a[None, 0] # (1,3,320,320)
b = torch.randn((1, 1, 320, 320)) # (1, 1, 320, 320)
b1 = b[0] # (1, 320, 320)
b2 = b[0].squeeze(0) # (320, 320)
b3 = b[0].unsqueeze(0) # (1, 1, 320, 320)
c = torch.randn((16, 2, 320, 320)) # (16, 2, 320, 320)
c1 = c[:, None, 1, :] # (16, 1, 320, 320)grad_mag = torch.sqrt(grad_x_r**2 + grad_y_r**2)
# 添加1e-8项
grad_mag = torch.sqrt(grad_x_r**2 + grad_y_r**2 + 1e-8)from torch._six import container_abcs
# 改为
import collections.abc as container_abcs>>> x = torch.randn(3, 4)
>>> x
tensor([[ 0.3552, -2.3825, -0.8297, 0.3477],
[-1.2035, 1.2252, 0.5002, 0.6248],
[ 0.1307, -2.0608, 0.1244, 2.0139]])
>>> mask = x.ge(0.5)
>>> mask
tensor([[False, False, False, False],
[False, True, True, True],
[False, False, False, True]])
>>> torch.masked_select(x, mask)
tensor([ 1.2252, 0.5002, 0.6248, 2.0139])x = torch.randn(3,4)
mask = torch.zeros(x.shape)
mask[x>0.5] = 1
result = torch.mul(x, mask)import torch
import cv2
mask = cv2.imread('./mask.png', 0)
mask = torch.from_numpy(mask)
edge = cv2.imread('./edge.png', 0)
edge = torch.from_numpy(edge)
mask1 = mask / 255.0
mask_region = mask1.ge(0.5)
mask_final = torch.zeros(edge.shape)
mask_final[mask_region==True] = 1
mask_final[mask_region==False] = 0
edge1 = torch.mul(edge, mask_final).numpy()# the follwoing path will be different for you - depending on your install method
$ cd env/lib/python3.10/site-packages/tensorrt
# create symbolic links
$ ln -s libnvinfer_plugin.so.8 libnvinfer_plugin.so.7
$ ln -s libnvinfer.so.8 libnvinfer.so.7
# add tensorrt to library path
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/env/lib/python3.10/site-packages/tensorrt/chmod -R 777 /storage/FT/pth/SCWSSOD/SCWSSOD28import torch
import torch.nn as nn
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)# Additional information
EPOCH = 5
PATH = "model.pt"
LOSS = 0.4
torch.save({
'epoch': EPOCH,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': LOSS,
}, PATH)model = Net()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
# - or -
model.train()tree_loss = TreeEnergyLoss().cuda()
preds = torch.randn((2, 21, 128, 128)).to(device='cuda')
low_feats = torch.randn((2, 3, 512, 512)).to(device='cuda')
high_feats = torch.randn((2, 256, 128, 128)).to(device='cuda')
unlabeled_ROIs = torch.randn((2, 512, 512)).to(device='cuda')pip install setuptools==59.5.026.报错`Assertion 't>=0' && 't参考资料:
images = torch.randn((8, 2, 3, 512, 512)).to(device='cuda')
masks = torch.randn((8, 2, 512, 512)).to(device='cuda')
image, mask = images[0], masks[0]
outputs = model(image)
loss = seg_loss([outputs[0], outputs[0]], mask)
optimizer.zero_grad()
loss.backward()
optimizer.step()
解决方案:将`torch.randn()`改为`torch.ones()`。
images = torch.ones((8, 2, 3, 512, 512)).to(device='cuda')
masks = torch.ones((8, 2, 512, 512)).to(device='cuda')28.张量(tensor)所在设备和加载到cpu/gpu:参考资料:
>> a = torch.randn((1,1))
>> a.device
device(type='cpu')
>> a = a.cuda()
>> a.device
device(type='cuda', index=0)
>> a = a.cpu()
>> a.device
device(type='cpu')问题:在使用Skimage处理单通道图片时进行了多余的转换:
MASK = color.rgb2gray(MASK) # shape of [h, w]解决方案:将上述代码改为,
if len(MASK.shape==3):
MASK = color.rgb2gray(MASK) # shape of [h, w]20.在`test.py`中设置GPU编号无效,仍使用GPU0参考资料:
GPU_ID=1
os.environ['CUDA_VISIBLE_DEVICES'] = str(GPU_ID)21.报错`tensorflow.python.framework.errors_impl.PermissionDeniedError:`参考资料:
22.在`bgnet.py`中导入上一层目录中其它文件夹中的包:参考资料:
import sys
sys.path.insert(0, '../utils')
from show_info import * +--bgnet
\----bgnet.py
+--utils
\----show_info.pyexport PYTHONIOENCODING=utf-8
export PYTHONLEGACYWINDOWSSTDIO=utf-8nvidia-smi | grep 'python' | grep 19398 | awk '{ print $5 }' | xargs -n1 kill -9